Intro to RL Chapter 3: Finite Markov Decision Process
时间: 2021-04-10 16:50:16 | 作者:斑马 | 来源: 喜蛋文章网 | 编辑: admin | 阅读: 106次
- 2023-11-24 11:00:14写好读书笔记对写作有哪些帮助
- 2023-11-09 01:01:18读书笔记的摘要和主要内容概述的区别
- 2023-10-30 19:00:44读书笔记对于阅读的重要性体现在哪里
- 2023-10-18 13:00:23用平板做读书笔记,推荐哪个软件
- 2023-09-20 11:00:39读书笔记就是摘抄句子吗
- 2023-08-29 17:01:33写读书笔记可以抄正在学的课文吗
- 2023-08-03 11:01:44你对读书笔记或者日记这种手写文字有怎样的认知 是不是和我一样有一种戒不掉的隐 你知道为什么么
- 2023-07-14 19:00:23如何写读书笔记,
- 2023-06-30 23:00:14如何教三年级学生学会写读书笔记
- 2023-06-29 12:01:30怎样引导孩子写读书笔记的感悟思考

3.1 The Agent-Environment Interface
Dynamics of finite MDP:3.2 Goals and Rewards
reward指明goal,但是不能给agent prior knowledge,比如下围棋,赢了一局给1分,但是agent并不知道该怎么下。what you want it to achieve, not how you want it achieved。3.3 Returns and Episodes
episodic tasks:有terminal states,cumulative reward直接加起来就好。continuing tasks:更多RL问题没有terminal states,一直跑啊跑啊跑啊,于是用discounting来计算discounted return,3.4 Unified Notation for Episodic and Continuing Tasks
用abosorbing state 将episodic tasks 和continuing tasks结合, 于是episodic tasks的reward变成
于是episodic tasks的reward变成 3.5 Policies and Value Functions
value function: how good it is for the agent to be in a given state (or how good it is to perform a given action in a given state).policy3.6 Optimal Policies and Optimal Value Functions
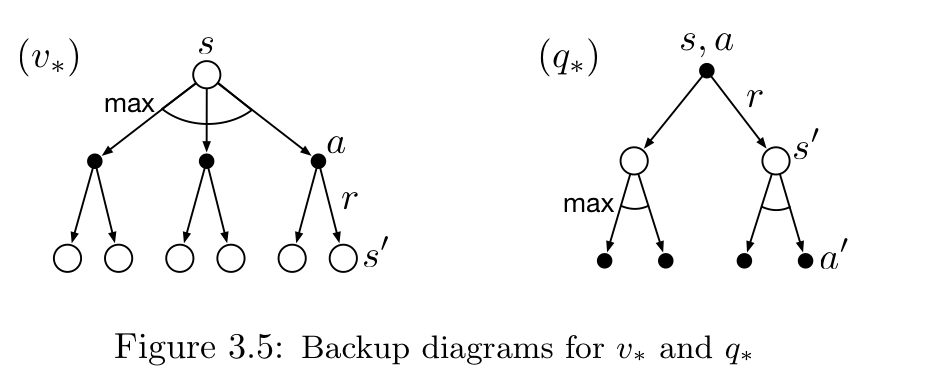
3.7 Optimality and Approximation
算力不够,时间不够,memory不够,必须用approximation。而且可能存在很多很少见的states,approximation不需要在这些states上做出很好的选择。这也是RL和其他解决MDPs方法一个主要区别。3.8 Summary
文章标题: Intro to RL Chapter 3: Finite Markov Decision Process
文章地址: http://www.xdqxjxc.cn/duhougan/101372.html
文章标签:读书笔记
[Intro to RL Chapter 3: Finite Markov Decision Process] 相关文章推荐:
- 最新读后感
- 热门读后感
- 热门文章标签
全站搜索