《Predicting clicks estimating the click-through rate for new ads》阅读笔记
时间: 2021-10-28 09:40:20 | 作者:xaropc | 来源: 喜蛋文章网 | 编辑: admin | 阅读: 102次
- 2023-11-24 11:00:14写好读书笔记对写作有哪些帮助
- 2023-11-09 01:01:18读书笔记的摘要和主要内容概述的区别
- 2023-10-30 19:00:44读书笔记对于阅读的重要性体现在哪里
- 2023-10-18 13:00:23用平板做读书笔记,推荐哪个软件
- 2023-09-20 11:00:39读书笔记就是摘抄句子吗
- 2023-08-29 17:01:33写读书笔记可以抄正在学的课文吗
- 2023-08-03 11:01:44你对读书笔记或者日记这种手写文字有怎样的认知 是不是和我一样有一种戒不掉的隐 你知道为什么么
- 2023-07-14 19:00:23如何写读书笔记,
- 2023-06-30 23:00:14如何教三年级学生学会写读书笔记
- 2023-06-29 12:01:30怎样引导孩子写读书笔记的感悟思考

说在前面的话:
这里是有关推荐系统领域一些经典论文的阅读笔记,论文列表来自于伯乐(RecBole)网站列出的经典模型列表:
笔者还是小白,刚开始阅读科研论文,还有许多地方做的不好,期待各位大佬们的建议和指点,感谢!!!
《Predicting Clicks: Estimating the Click-Through Rate for New Ads》阅读笔记
1. 问题介绍
按效果付费/每次点击付费(pay-per-performance with a cost-per-click)是一种非常通用的在线广告形式。每次广告被用户点击时,搜索引擎就会得到一笔收入。因此,为了最大化收入与用户满意度,需要对用户的点击行为进行预估。对于已有的广告,可以通过历史数据预估广告的点击率(click-through rate, CTR)。但是这一方法预测的结果方差较大,并且不能应用在新进入系统的广告中。
2. 本文改进与动机
本文提出了一种基于广告时长、用词、广告指向的页面以及相关广告的统计数据的预测模型,用来合理预测广告未来的点击率。
对于广告投放问题而言,关键的任务是决定哪些广告该被投放以及以何种顺序投放。该文认为,广告投放的位置会显著影响点击率,待投放的广告比待填充广告的槽位要多得多,因此选择一个恰当的投放顺序非常重要。
因此为了最大化广告质量和总收入(maximize ad quaility(as measured by user clicks) and total revenue),大部分搜索引擎基于以下公式排列广告:
上式中前半部分表示点击该广告的概率,后半部分则是该广告的定价。
文章中对广告的点击率提出了一个假设:广告会依时间收敛至一个潜在的、真实的点击率(an underlying true click-through rate)。对于之前已经展示过很多次的广告,可以通过极大似然估计预测其被点击的概率(实际上是否点击一个广告服从0-1分布,而0-1分布参数的极大似然估计与使用频率估计是等价的)。但是另一个问题是,相对低的CTR会导致估计的方差较高,想要让估计值与真实值之间的误差足够小的话需要大量历史数据。此外,排序对收入的显著影响以及日益增长的广告投放需求都给点击率预测提出了更多要求,因此需要提出一个不依赖历史观察的点击率预测方法。
3. 相关工作
文章中主要提到的相关工作主要是Regelson与Fain使用与新广告具有相同竞价关键词(bid terms, 就是搜索什么词的时候会展示该广告)或同属一个主题簇(topic cluster)的现存广告的点击率预估新广告点击率。文章认为关键词相同的广告间点击率方差也很大,对于这一问题需要额外考虑关键词以外的广告特征。
4. 搜索广告框架
文章在这一部分主要是对点击率进行了建模并提出了以下公式:
即将给定广告与展示位置后,广告被点击的概率取决于该广告在该位置被看见的概率以及看见后点击的概率。这里文章假设广告在没有被看到的情况下被点击的概率为0。
文章还做了进一步的假设,一是认为广告在被看见后其被点击的概率与广告所处的位置无关,二是认为广告被看见的概率与广告本身无关,三是认为广告所处的位置与其他被展示的广告无关。因此可以将上式进一步简化:
下面,文章重新定义CTR为广告被看见后点击的概率p(click|ad, seen),在此基础上结合广告在不同位置被看见的概率就可以来估计广告的点击率。
已经被展示了很多次的广告的CTR很好估计。文章认为,广告如果被点击了,那么一定是被看到了,如果广告没有被点击,它也有可能被看到了。因此,文章认为广告被看到的次数(the number of views of an ad)等于广告被点击的次数加上它被估计为看到但是没有点击的次数(the number of times it was estimated to have been seen but not clicked)(我还不太明白,后者是怎么估计得出的?)。广告在不同位置被看见的相对概率可以通过在页面的不同位置向用户相同的广告来实验测量,因此这些广告的CTR就可以简单地通过点击次数除以总浏览量(total number of views)获得。讲这一部分是为了计算训练数据中的广告的真实点击率。
5. 数据集
文章使用的数据来自微软搜索引擎,数据集中的每一条广告包括以下几条信息:
指向的页面(Landing Page):用户点击广告后转向的页面竞价关键词(Bid term):即搜索什么结果时,广告会被展示标题(Title):用户能看到的广告标题主体(Body):用户能看到的广告文本描述链接(Display URL):用户能看到的广告的链接点击量(Clicks):广告自从投入系统后被点击的次数浏览量(Views):广告自从投入系统后被浏览的次数(见上一部分)在数量上,数据集一共包括10000个广告主的一百万条广告,这些广告与五十万个关键词配合,还有超过十万条独特的广告文本。在搜索过程中,如果广告相同但是搜索关键词不同,那么文章将这两次展示的广告视作不同的(unique),因为不同关键词下广告的CTR方差比较大。
在广告与搜索词的匹配模式上(match type),文章并不区分精准匹配(exact match)与模糊匹配(broad match),前者指广告严格在搜索特定关键词时展示,后者指关键词与搜索词的关联可以更松散,比如关键词是搜索词的子集时也展示该广告。
文章将数据按照广告主进行切分,这是为了避免训练集-测试集污染,因为其目标是预测一个“全新”的广告,“全新”的意思是对该广告以及投放该广告的广告主的其他广告都一无所知。训练集、验证机、测试集的划分比例为7:1:2。
文章还排除了具有特殊广告管理机构的广告主,这是因为他们的广告往往不同于一般的趋势,并且并不属于所有广告主中的主流。为了保证显著的差异,文章从每一个不同的广告主处仅随机选取1000个广告。
同样,为了减少数据稀疏带来的噪音以及仅高曝光度广告带来的偏见,文章仅选取了那些浏览次数大于100的广告。
6. 模型
这篇文章提出的模型是一个Logistic Regression模型,公式表达如下: 这里CTR表示预测的点击率,fi(ad)表示广告ad的第i个特征值,wi表示该特征对应的权重。
优化上使用了limited-memory Broyden-Fletcher-Goldfarb-Shanno Method(L-BFGS)方法,笔者对这个方法也不是很了解,不过这不是这篇文章的重点,网上有很多有关此算法的博客,大家有兴趣的话可以自行搜索查阅。损失函数上使用了交叉熵损失函数,和一个均值为0,方差为0.1的高斯权重先验(实验获得),以及一个值为1的偏置。
作者还为每个特征补充了两个衍生特征 ,并对训练集上的特征进行了标准化(0均值,单位标准差),并将参数用于测试集上。对于存在异常值的特征,将其标准差截断为5。文章使用了KL散度与均方误差(MSE)作为评价指标。
7. 特征设计
7.1 与竞价关键词有关的特征(Terms CTR set)
这一部分的特征主要是使用了与当前广告关键词具有某种关系的广告的点击率,可以分为与当前广告使用相同关键词和相关关键词两类。
7.1.1 使用相同关键词(Term CTR):
上面式子里, 表示训练集中所有广告的平均CTR,
表示关键词与当前广告相同的所有广告的数量(不区分词序),
表示这部分广告的平均CTR。这里使用总均值的目的为为了防止某些广告没有被浏览过,因此加上总均值进行平滑,α是超参,实验中取值为1(作者认为实验结果对α的取值不敏感)。
7.1.2 使用相关关键词(Related Term CTR):
文章中首先为具有相关关键词的广告集合 ,公式先贴在下面:
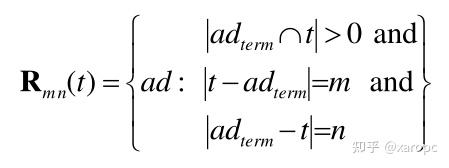
这个集合中包含的广告i的性质是,当从t中移除m个元素、从广告i的关键词中移除n个元素后,两者相同,并且t与广告i的原始关键词至少有一个相同的词。举个例子,如果t是“red shoes”,广告关键词是“buy red shoes”,那么这个广告应该放入 。因为从t中移除0个词(不移除),从原关键词中移除1个词(buy),二者相同,并且原本就有两个词相同(大于等于1)。同样地,“shoes”属于
,“blues shoes”属于
,
表示的就是精准匹配(exact match)也就是上一种情况。
给定了某个集合 后,就可以计算这个集合中广告的平均CTR了。计算的公式为:
看着很复杂,其实就是平均值。作者也像Term CTR一样对这个特征采取了同样的平滑策略。这里m和n的取值来自集合{0,1,2,3,*},*代表任意自然数。
除了CTR以外,作者还将这两类集合中的元素个数也作为特征参与计算。实验结果如下:
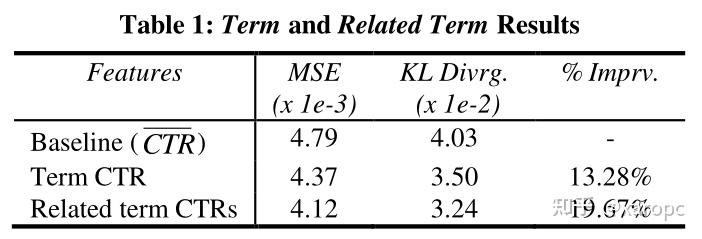
可以看出,加入关键词特征确实增强了模型的表现。
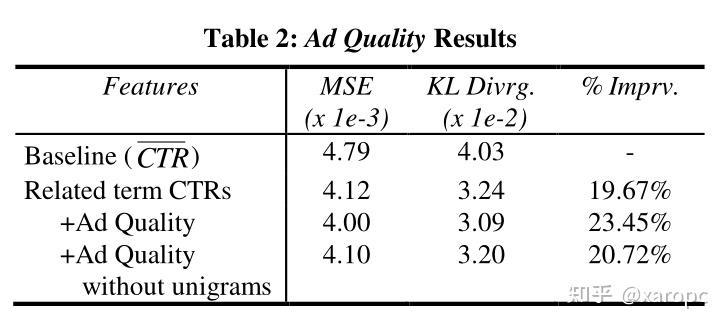
7.2 与广告质量有关的特征(Ad quality set)
相同关键词下,广告的CTR差距也比较大,因此需要考虑广告本身的特征。
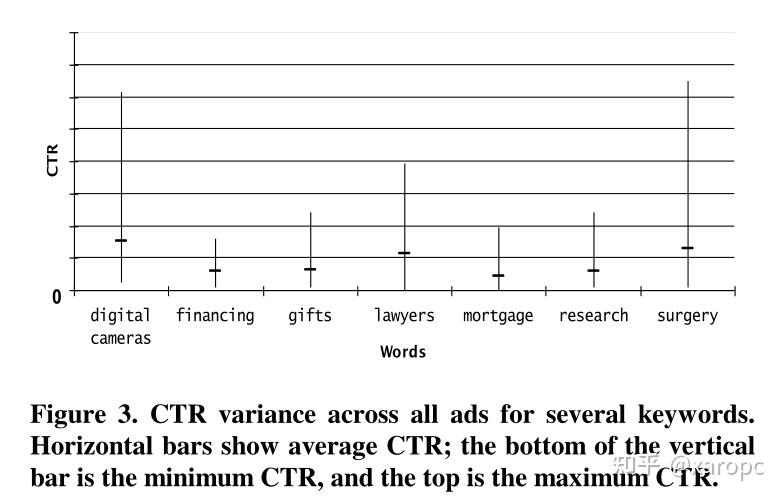
因此,作者从广告外观、注意力、广告主名望、广告指向页面的质量、广告与搜索关键词的相关程度这五个类别进行考量,设计了81个特征,比如标题词数、使用的词汇等等。作者还考虑了unigram特征,考察了所有广告文案中出现频率最高的一万个词,并使用0-1二值表示。他们认为,热门词汇与广告的CTR之间存在某种隐含的关系,高CTR的广告更倾向于使用一小部分词。
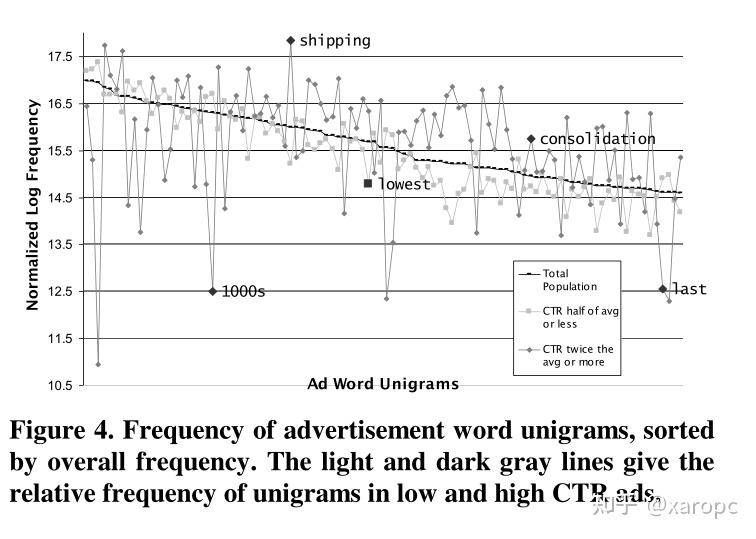
实验结果如下,增加了广告质量的特征也带来了模型表现的提高。作者分析认为,unigrams特征起到了重要的作用,甚至超过了人工特征。
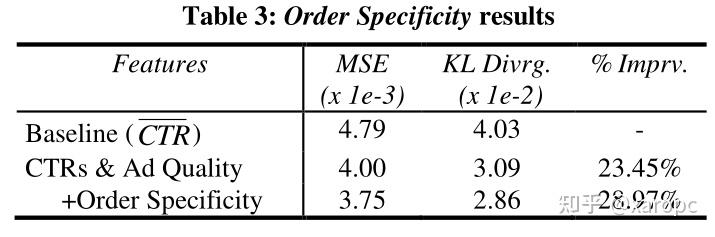
7.3 与广告order有关的特征(Order entropy set)
order可以理解为广告主向搜索引擎提出的一个请求(?),里面包括了有关广告的一些信息。


上面是文中举出的两个例子,要注意的是,触发不同关键词(Terms)时呈现的广告被认为是不同的。作者认为,广告对目标群体的指向性也会影响广告的CTR,他们用关键词的类别熵来衡量广告的指向性。具体做法是先在一个数据集(Look Smart Directory ,一个搜索引擎的目录)上训练出一个文本分类算法(这里用的是朴素贝叶斯),然后对数据进行网络搜索,对搜索结果进行分类(一共有74类),并计算类别分布的熵。文中并没有介绍熵是如何计算的,笔者个人认为应该是使用分类器的输出结果,如果类别分布越均匀,那么熵应该越小,反之越大,越大就越说明这个关键词的指向性比较强。另外,作者还考虑了order中不重复的关键词的数量。
实验结果表明,这一组特征也显著提高了模型的表现,上述两个特征起到了明显的作用。
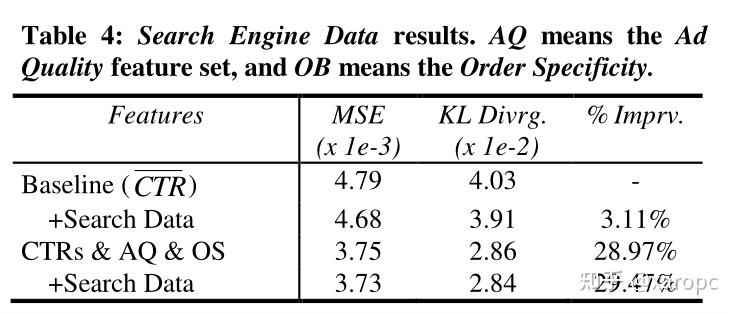
7.3 与Search Data有关的特征(Search data set)
作者在这一部分提出,我们所使用的特征不仅可以来自广告本身,也可以来自如百科全书等外部资源,因此他们增加了两个新的特征:竞价关键词在网络上出现的近似频率以及搜索引擎使用这些关键词作为搜索请求(query)的频率。获取前者的做法是,在搜索引擎上搜索广告的关键词,然后记录引擎声称的、包含该关键词的结果的数量;获取后者的办法是在近三个月的搜索记录中统计查询当前广告关键词的频次。从实验结果来看,在baseline上单独增加Search Data相关特征有提升,但是在上文基础上加这一特征没什么提升,可能是这些特征之间是有重叠的(overlap)。
8. 关于实验结果的讨论
8.1 特征的使用情况
上文中,作者设计了四类特征,在这一部分内容中,作者分析了这四类特征单独作用时对模型表现的贡献。当不使用任何附加术语或相关术语CTRs,且不使用其他特性集时,我们测量了每个特性集KL-divergence的减少%(如前表所示)。改进如下:广告质量特征集12.0%(单是unigram特征10.2%),Order熵集8.9%,搜索数据集3.1%。正如预期的那样,如果我们在基线中包含术语CTR,我们会得到类似的改进,尽管有所减少。
之后作者分析了模型给予不同特征、不同unigram的权重,并进行了一些分析。不是说权重越高就说明某个特征越重要,因为这些特征之间并非相互独立的。unigram部分主要是从定性角度来看的,作者认为广告中包含一些比较有名望的实体(entities)能够更让广告的点击率更高。

作者最后讨论了有关特征冗余的问题,他们认为冗余的特征具有更好的鲁棒性,也给攻击带来了更高的成本,并且能够更容易地进行攻击检测。
8.2 初始化后的演进(Evolution After Initialization)
(这个标题我也不知道咋翻译)
这一部分,作者主要是想讨论单纯使用历史数据的情况下,需要多少浏览量估计才能与模型估计一样好,也就是前者的误差什么时候能接近后者。这里单纯使用历史数据指的就是文章之前一直用来比较的baseline,模型则是指使用了全部特征的逻辑回归模型。作者将估计的误差定义为 解释一下,
就是对广告真实的潜在的点击率的最佳估计。
就是模型的先验预测,α则是用来设定先验的强度。下面这个式子隐含这样一个假设:除了实际的点击和浏览次数外,还展示了当前广告α次,并且观察到它被点击了
次。CTR应该就是该广告的真实点击率。
是一个二项分布。大意就是计算最佳估计与真实点击率的绝对误差在上面这个二项分布上的数学期望。
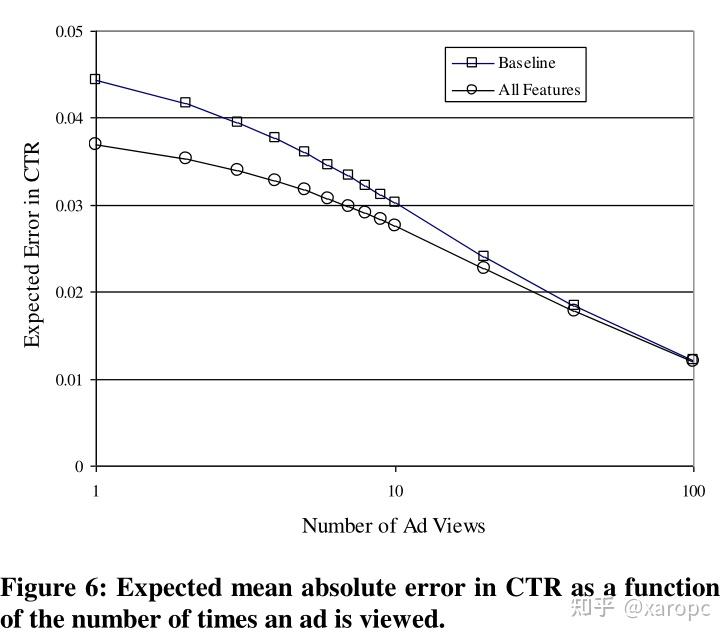
实验结果表明,baseline与全特征模型在50-100次浏览浏览量左右差距基本就很小了,这也体现出模型在广告上线前期有很大价值。
8.3 关于广告浏览次数
文章在选取训练数据时设置了一个过滤阈值,作者想要继续研究这个阈值的影响。作者认为,这个阈值越高,训练数据噪音越少,但也会偏离新广告的表现。结果表明,提高阈值至1000后,设计的特征能够更好地改善模型表现。作者还有一个观察发现,即浏览量超过1000的广告的平均CTR要比超过100的广告的平均CTR高出40%。
9. 未来展望
在这一部分,作者主要对后续工作提出了一些展望。包括设计标准数据集、让点击率预估依赖于用户的查询、让广告商依据结果改进广告、加入有关用户行为的考量、人类判断以及有关广告主的信息等。
10. 总结
这篇文章提出了一个逻辑回归模型,能够在baseline基础上减少30%的误差,这些误差减少主要来自同一个term内的广告误差的减少与cross terms情况下的误差减少。前者是使用了有关广告质量的信息,后者使用了相关term的广告的点击率数据。
11. 笔者的一些感想
这篇文章发布时间很早,使用的模型也比较简单,比较大的特点就是设计了一些特征。不过有意思的特点是,作者人工设计的特征效果不如unigram这种自动统计的“特征”。
这篇文章也是作者细致阅读的第一篇推荐系统的论文,感觉现在还不太会读论文,效率比较低,以后还要多改进。笔者经验比较少,还处于建立框架的阶段,因此也很难有什么看法,以后要多加油!
[《Predicting clicks estimating the click-through rate for new ads》阅读笔记] 相关文章推荐:
- 最新读后感
- 热门读后感
- 热门文章标签
全站搜索