Intro to RL Chapter 13: Policy Gradient Methods
时间: 2021-09-19 08:42:04 | 作者:斑马 | 来源: 喜蛋文章网 | 编辑: admin | 阅读: 107次
- 2023-11-24 11:00:14写好读书笔记对写作有哪些帮助
- 2023-11-09 01:01:18读书笔记的摘要和主要内容概述的区别
- 2023-10-30 19:00:44读书笔记对于阅读的重要性体现在哪里
- 2023-10-18 13:00:23用平板做读书笔记,推荐哪个软件
- 2023-09-20 11:00:39读书笔记就是摘抄句子吗
- 2023-08-29 17:01:33写读书笔记可以抄正在学的课文吗
- 2023-08-03 11:01:44你对读书笔记或者日记这种手写文字有怎样的认知 是不是和我一样有一种戒不掉的隐 你知道为什么么
- 2023-07-14 19:00:23如何写读书笔记,
- 2023-06-30 23:00:14如何教三年级学生学会写读书笔记
- 2023-06-29 12:01:30怎样引导孩子写读书笔记的感悟思考

13.1 Policy Approximation and its Advantages
policy parameter只要是differentiable,只要 第三个优势是有时候policy function更容易得到。有的task state少action少但policy复杂,那就用action-value methods,有的policy简单,env复杂,那就policy methods。最后,用policy function可以很方便地使用prior knowledge,这经常是使用policy-based learning但主要原因。
第三个优势是有时候policy function更容易得到。有的task state少action少但policy复杂,那就用action-value methods,有的policy简单,env复杂,那就policy methods。最后,用policy function可以很方便地使用prior knowledge,这经常是使用policy-based learning但主要原因。13.2 The Policy Gradient Theorem
除了上面的advantage,还有一些理论上的advantage。policy parameterization在action之间prob是平滑的,不像action-value based methods,action轻轻一变value就可能变化巨大。这也让policy parameter更容易converge。episodic 和 continuing case有不一样但performance measureconstant proportionality 是 average length of an episode,对于continuing case 为 1。 值on-policy distribution (see P199)。
13.3 REINFORCE: Monte Carlo Policy Gradient
all-actions methods, 直接从 (13.5) 得到, 用得到policy parameter update:
 下图为REINFORCE 在 example 13.1 的结果:
下图为REINFORCE 在 example 13.1 的结果: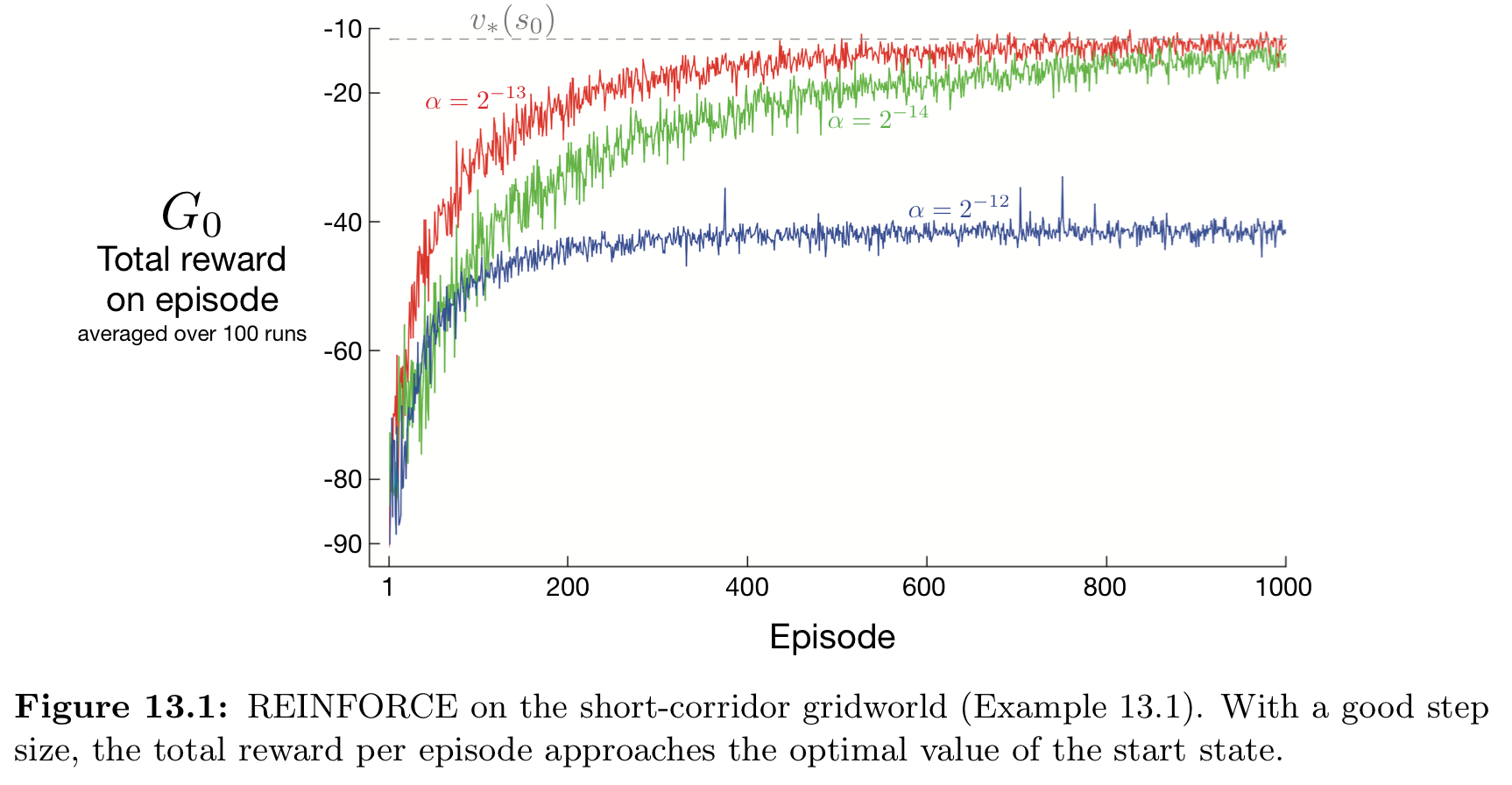 用的是标准的SGD,REINFORCE能保证converge,虽然可能high variance因此学起来慢。
用的是标准的SGD,REINFORCE能保证converge,虽然可能high variance因此学起来慢。13.4 REINFORCE with Baseline
(13.5) 可以加上一个baseline文章标题: Intro to RL Chapter 13: Policy Gradient Methods
文章地址: http://www.xdqxjxc.cn/duhougan/123023.html
文章标签:读书笔记
[Intro to RL Chapter 13: Policy Gradient Methods] 相关文章推荐:
- 最新读后感
- 热门读后感
- 热门文章标签
全站搜索