Streamlit 视频交互式笔记
时间: 2021-07-06 20:26:46 | 作者:一只小胖子 | 来源: 喜蛋文章网 | 编辑: admin | 阅读: 118次
- 2023-11-24 11:00:14写好读书笔记对写作有哪些帮助
- 2023-11-09 01:01:18读书笔记的摘要和主要内容概述的区别
- 2023-10-30 19:00:44读书笔记对于阅读的重要性体现在哪里
- 2023-10-18 13:00:23用平板做读书笔记,推荐哪个软件
- 2023-09-20 11:00:39读书笔记就是摘抄句子吗
- 2023-08-29 17:01:33写读书笔记可以抄正在学的课文吗
- 2023-08-03 11:01:44你对读书笔记或者日记这种手写文字有怎样的认知 是不是和我一样有一种戒不掉的隐 你知道为什么么
- 2023-07-14 19:00:23如何写读书笔记,
- 2023-06-30 23:00:14如何教三年级学生学会写读书笔记
- 2023-06-29 12:01:30怎样引导孩子写读书笔记的感悟思考

Streamlit是一款基于Python语言的开源库,支持通过Python编写简单的几行代码来直接生成丰富的前端可交互式界面. 在数据分析,智能AI团队场景中使用广泛.同时在个人应用场景开发上也非常的高效,简单实用.
有了它,我们能在绝大多数常见的应用场景中快速开发,免去再单独开发一套前端Web界面,不必像传统应用开发时,在写完后台业务代码的API后,还要再写前端来请求API读数据. 本文就来简单介绍一下,在具体场景中使用Streamlit它能解决什么问题. 官网介绍从这里点入:
https://streamlit.io/streamlit.io1.场景示例
使用Streamlit编写一个类似"飞书妙记"会议笔记,以及"十行笔记"应用.满足视频内容界面交互的功能.实现快速视频检索/播放/笔记记录及管理,以及对视频字幕内容进行定制分析等.这里的示例只是streamlit的基础功能展示,好让大家知道streamlit在开发交互式应用上是多么的高效.
十行笔记|专业的音视频AI笔记videoai.perspectivar.com下面先放几张最终的交互效果图:
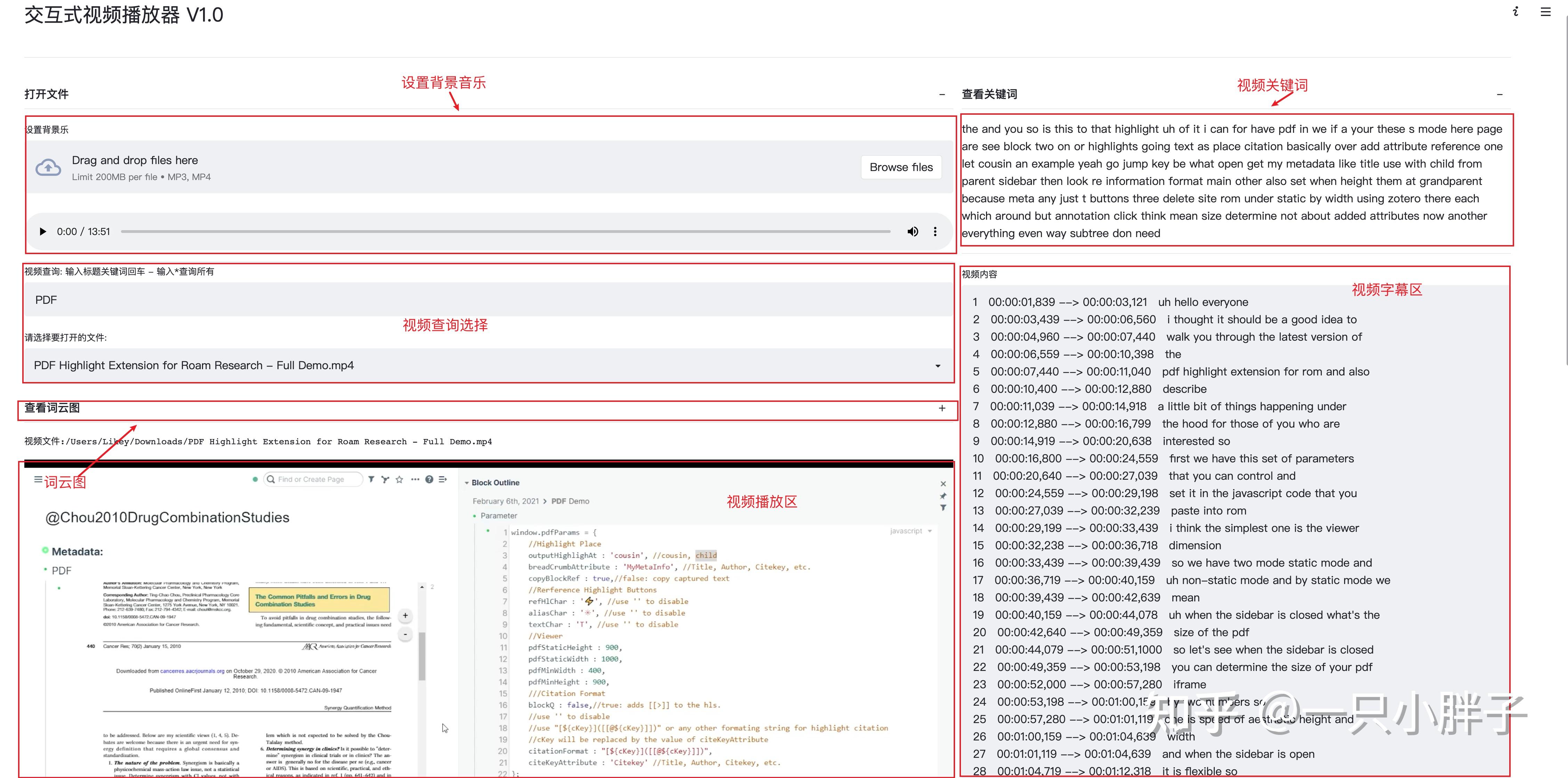


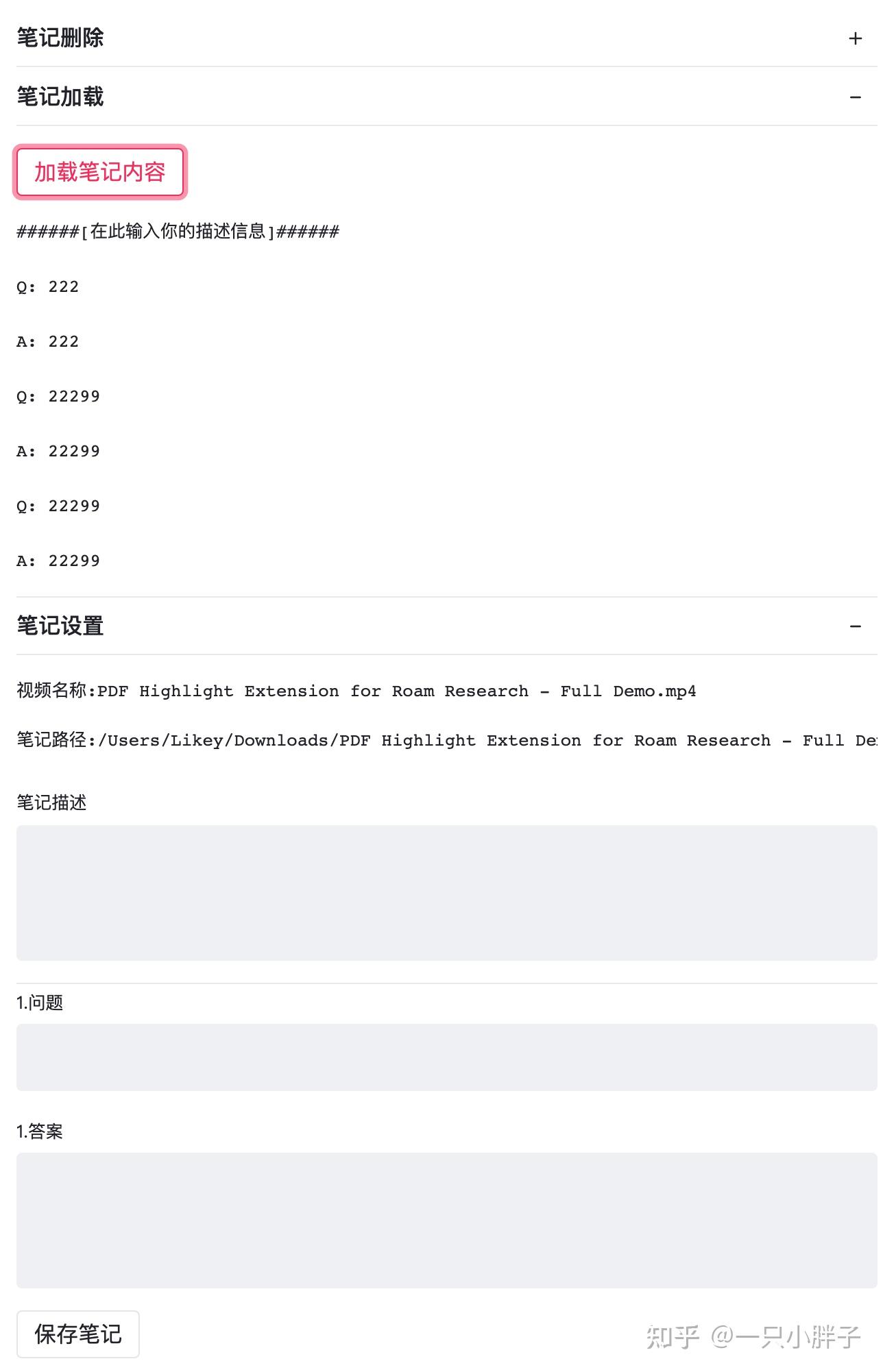
2.使用流程
基础配置: 安装streamlit pip包 | 下载实例代码(另存为demo.py)一.运行streamlit应用在终端/CMD下运行 streamlit run demo.py 来打开浏览器
二.直接在浏览器中操作,使用视频标题内容来检索内容(分析词频,快速检索,保存笔记等)
如果本地已准备视频和字幕,以下第三/第四步骤可跳过,不然使用第三/第四步骤来准备三.准备视频 通过直接下载或录制的方式把视频保存到目录上或者使用MPV的剪辑功能
四.生成字幕 下载并配置好VideoSrt软件,并把第三步的视频批量导入转换成字幕或文本
一. 基础配置
不再具体介绍PyCharm,Python的安装,Python我使用的是3.9的版本,PyCharm为社区版本.如下代码中第二行stream hello运行后浏览器会自动打开一个网址,显示了官方案例效果.
# 终端pip安装$ pip install streamlit # 安装软件$ streamlit hello # 打开官方示例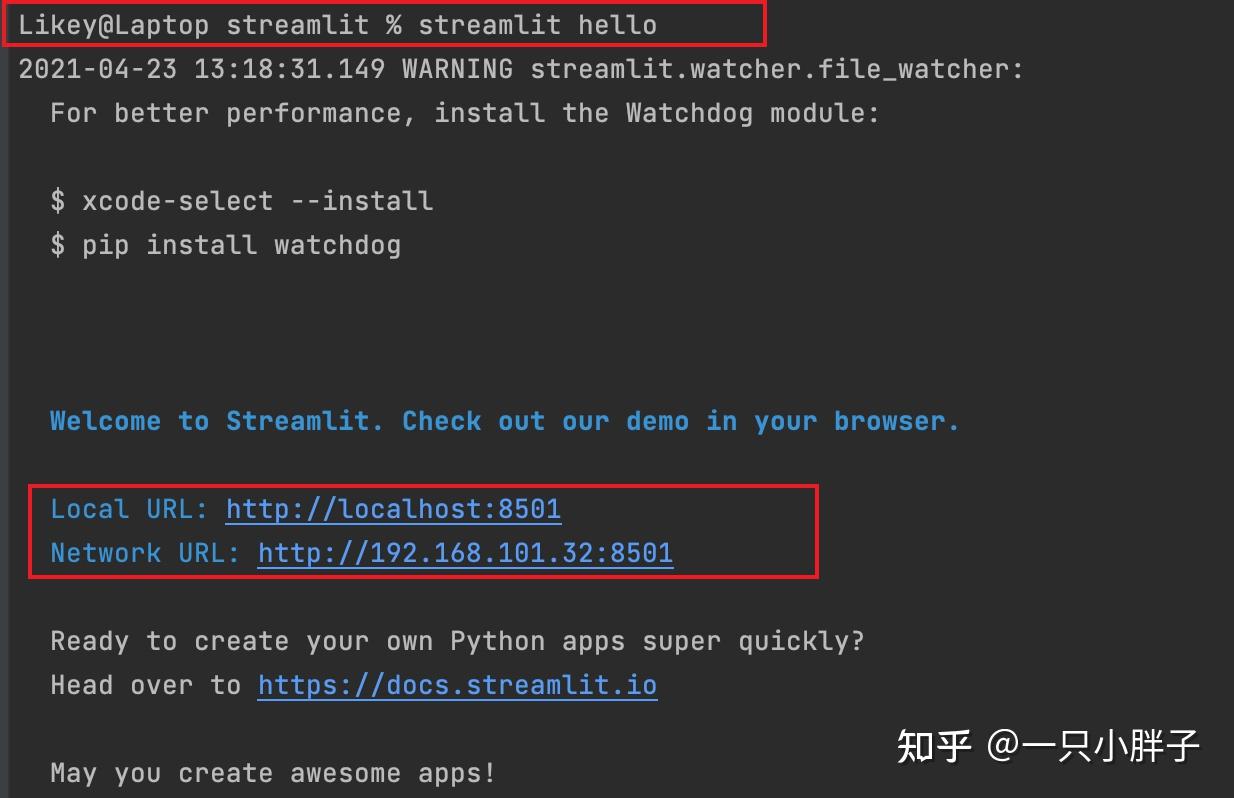
二. 实例代码
这里直接放置代码内容及链接了,详细的说明及注释都写在代码里了,所以这里不再过多的解释.
GitHub内容链接: 实现飞书妙记/十行笔记等软件类似功能 , 如下为代码内容直接展示,方便上
不了外网的同学. 复制粘贴保存至demo.py后, streamlit run demo.py 运行可看到效果.
提示: 注意按自己的情况修改参数为视频目录 self.mpv_gen_path = " 你的视频文件夹目录 "
#### 代码存为demo.py 通过streamlit run demo.py运行 ##### https://gist.github.com/sz1262021/b1e12e0fbd6570f91d444e77fb462415# !/usr/bin/env python3# -*- coding: utf-8 -*import streamlit as stimport reimport osimport jiebafrom collections import Counterimport pyecharts.options as optsfrom pyecharts.charts import WordCloudfrom pyecharts.globals import ThemeType# 实现飞书妙记/十行笔记等软件类似功能# 作者: 一只胖子# 版本: V0.1# 知乎链接: https://www.zhihu.com/people/lxf-8868class VideoShowMain: def __init__(self): self.app_main_name = "交互式视频播放器 V1.0" # 窗口标题 self.player_open_file_name = "" # 正在播放文件路径 self.player_open_file_srt = "" # 视频文件字幕信息 self.html_file_name = "./srt_basic.html" # 生成词云图html文件位置 self.keywords_stat_content_str = "" # 关键词内容数据 self.keywords_stat_most_common = 120 # 返回几个关键词 self.mpv_gen_path = "/Users/Likey/Downloads" # 学习的视频来源 self.support_media_type = [".mp4", ".avi", ".mkv", ".mov", ".m3u8"] # 支持播放的视频类型 self.srt_all_content = "" # 返回的全部字幕信息 self.srt_word_content = "" # 返回的字幕文本信息 self.question_input_form_num = 1 # 笔记默认填空表格数 self.player_open_file_s_name = "" # 视频文件名称 self.book_note_file_path = "" # 笔记保存的路径 self.select_box_list = [] # 文件下拉列表的内容 # 文本分词操作 def split_word(self, text): word_list = list(jieba.cut(text)) # 去掉一些无意义的词和符号,我这里自己整理了停用词库 with open('../停用词库.txt') as f: meaningless_word = f.read().splitlines() result = [] # 筛选词语 for i in word_list: if i not in meaningless_word: result.append(i.replace(' ', '')) return result # collections的使用 https://zhuanlan.zhihu.com/p/108713135 # 统计词频 def word_counter(self, words): # 词频统计,使用Count计数方法 words_counter = Counter(words) # 将Counter类型转换为列表,这里只返回前 1000 条数据 words_list = words_counter.most_common(1000) return words_list # 制作词云图 def word_cloud(self, data): ( # width='600px', height='500px', theme=ThemeType.MACARONS) # 设置词云图的基本属性 WordCloud(init_opts=opts.InitOpts(width='100%', theme=ThemeType.MACARONS)).add( series_name="热点分析", # 添加数据 data_pair=data, # 字间隙rue word_gap=3, # 调整字大小范围 word_size_range=[15, 60], shape="cursive", # 选择背景图,也可以不加该参数,使用默认背景 # mask_image='购物车.jpg') ).set_global_opts( # title_opts=opts.TitleOpts( # title="热点分析", title_textstyle_opts=opts.TextStyleOpts(font_size=12) # ), tooltip_opts=opts.TooltipOpts(is_show=True), ).render(self.html_file_name) # 输出为html格式 ) # 获取词云图网页内容,通过streamlit网页组件展示 def get_word_cloud_html_str(self, html_file_name_): st_file_arr = [] st_file_lines = open(html_file_name_).readlines() for st_file_str in st_file_lines: st_file_arr.append(st_file_str.strip("")) st_file_arr_str = " ".join(st_file_arr) return st_file_arr_str # 生成词云图 def gen_word_cloud_html(self, s_text): sword = self.split_word(s_text) word_stat = self.word_counter(sword) self.word_cloud(word_stat) # 返回前self.keywords_stat_most_common个关键词(默认按词频降序) srt_keywords_stat = "" # for x_obj in word_stat[:5] # 取列表中前5个元组 # 元组取值 x_obj[0], x_obj[1] # 只返回关键词内容,不含统计数 for (s_keyword_value, s_keyword_count) in word_stat[:self.keywords_stat_most_common]: srt_keywords_stat = srt_keywords_stat + " " + s_keyword_value # 返回关键词内容字符串 self.keywords_stat_content_str = srt_keywords_stat return srt_keywords_stat # 字幕加载函数 def load_srt_content(self): s_line_str = "" # 字幕内容(包括时间/序号) s_content = "" # 字幕内容(只返回文本内容) with open(self.player_open_file_srt, encoding="utf-8", mode="r") as f: split_count_ = 0 # 用于按固定行分割,统计数 for line_str in f.readlines(): # 去除空行(第4行) if len(str(line_str).strip().strip(" ")) == 0: continue # 当前匹配次数 split_count_ = split_count_ + 1 line_str = line_str.strip() # 去换行符号 # 每6行加换行符号 if split_count_ % 3 == 0: s_line_str = s_line_str + line_str + "xx:" # 分割符号 else: s_line_str = s_line_str + line_str + " " # 每3行取一次文本 if split_count_ % 3 == 0: s_content = s_content + line_str + " " # 返回所有字幕信息 self.srt_all_content = s_line_str # 返回字幕文本信息 self.srt_word_content = s_content # 按关键字搜索视频文件 def search_video_file(self, s_key_word): # for f_name in os.listdir(mpv_gen_path): # os.listdir 在文件夹不存在时会报错 if not os.path.isdir(self.mpv_gen_path): st.error("视频主存储目录不存在!") st.text("{}{}".format("视频目录:", self.mpv_gen_path)) # 获取传入路径下的: 当前目录, 子目录列表, 文件列表 for f_path, dir_names, f_names in os.walk(self.mpv_gen_path): # 去除.开头的隐藏目录及不支持的视频格式 f_names = [f_name for f_name in f_names if not f_name.startswith(".") and f_name.__contains__(".") and str("." + f_name.split(".")[1]) in self.support_media_type] # 按关键字查询过滤视频文件名 if s_key_word == "*": self.select_box_list = f_names # 所有的视频文件列表值 pass else: f_names = [f_name for f_name in f_names if str(f_name).__contains__(s_key_word)] # 选择的视频文件路径 if f_names: video_file_name = st.selectbox("请选择要打开的文件: ", f_names) video_path_str = "{}{}{}".format(f_path, "/", video_file_name) # 播放文件位置 self.player_open_file_name = video_path_str # 返回视频播放地址 # 字幕文件位置 self.player_open_file_srt = os.path.splitext(video_path_str)[0] + ".srt" else: st.error("未查询到匹配结果!") break # 只返回根目录下的内容,其它文件夹忽略 # 界面初始化配置 st.set_page_config( page_title="交互式视频播放器", # st.get_option(""), page_icon=":shark", layout="wide", initial_sidebar_state="auto", ) # 界面初始化入口 def ui_main(self): # with st.beta_container(): # st.components.v1.html("<hr>") # st.markdown("<hr>", unsafe_allow_html=True) container1 = st.beta_container() # streamlit界面布局(分列显示) col1, col2 = st.beta_columns([5, 3]) # 各列占宽比例 # 使用容器简单布局 with container1: st.header(self.app_main_name) st.markdown("<hr>", unsafe_allow_html=True) # 左侧的内容 with col1: # 设置背景音乐 with st.beta_expander(label="打开文件", expanded=False): # 多文件载入 uploaded_files = st.file_uploader("设置背景乐", type=['mp3', 'mp4'], accept_multiple_files=True) for uploaded_file in uploaded_files: bytes_data = uploaded_file.read() # https://github.com/streamlit/streamlit/issues/904 # st.write("文件属性:", uploaded_file.name, uploaded_file.size,uploaded_file.type, uploaded_file.id) # self.player_open_file_name = "/Users/Likey/Downloads/Learning Human Anatomy with SuperMemo.mp4" st.audio(bytes_data) # 按标题关键词搜索 search_key = st.text_input("视频查询: 输入标题关键词回车 - 输入*查询所有", "*") if search_key: # 视频播放地址已设置 if self.player_open_file_name != "": # 字幕文件位置 self.player_open_file_srt = os.path.splitext(self.player_open_file_name)[0] + ".srt" pass else: self.search_video_file(search_key) else: st.error("未输入标题查询关键词!") # 视频播放地址已设置 if self.player_open_file_name != "": # 字幕文件位置 self.player_open_file_srt = os.path.splitext(self.player_open_file_name)[0] + ".srt" pass if not os.path.exists(self.player_open_file_name): # st.error("视频文件: {} 不存在!".format(self.player_open_file_name)) pass if not os.path.exists(self.player_open_file_srt): st.error("未找到有效的字幕文件!") st.text("{}{}".format("字幕文件:", self.player_open_file_srt)) else: self.load_srt_content() # 加载字幕文件 # 生成词云图 srt_keywords_str = self.gen_word_cloud_html(self.srt_word_content) word_cloud_html_str = self.get_word_cloud_html_str(self.html_file_name) # 显示云图(不能用%绝对长宽 expected one of: int, long, float) r_width = 1100 r_height = 580 r_scrolling = True # st.components.v1.html(word_cloud_html_str, width=r_width, height=r_height, scrolling=r_scrolling) with st.beta_expander("查看词云图"): # 指定高度值,未设置宽度 st.components.v1.html(word_cloud_html_str, height=r_height, scrolling=r_scrolling) st.text("") # 可以用st.write("r")来换行并解析网页链接 st.text("视频文件:" + self.player_open_file_name) # st.markdown("<hr>", unsafe_allow_html=True) # 显示视频文件 if os.path.isfile(self.player_open_file_name) and os.path.exists(self.player_open_file_name) and os.path.splitext(self.player_open_file_name)[1] in self.support_media_type: st.video(self.player_open_file_name) else: st.error("未找到有效的视频文件!") # # 展示关键字并设置样式 # st.text("关键词: ") # st.markdown("{}{}{}".format("**", self.keywords_stat_content_str, "**")) st.markdown("<hr>", unsafe_allow_html=True) s_question_answer_content = "" # 要添加的笔记内容 # 获取文件名称部分 player_open_file_name_ = os.path.split(self.player_open_file_name)[1] # 如果是网址的形式 if str(player_open_file_name_).__contains__("?"): # 文件名称 player_open_file_name_ = player_open_file_name_.split("?")[0] # 视频播放名称(本地OK,在线的短路径则需优化) self.player_open_file_s_name = player_open_file_name_ # 笔记文件名称 if player_open_file_name_ and player_open_file_name_ != "": self.book_note_file_path = "{}{}{}".format(self.mpv_gen_path, "/", os .path.splitext(player_open_file_name_)[0] + ".txt") with st.beta_expander("笔记删除"): if st.button("删除我的笔记"): if os.path.exists(self.book_note_file_path): os.remove(self.book_note_file_path) st.success("笔记删除成功!") else: st.error("笔记已不存在!") with st.beta_expander("笔记加载"): if st.button("加载笔记内容"): if os.path.exists(self.book_note_file_path): with open(self.book_note_file_path, encoding="utf-8", mode="r") as f_: st.text("".join(f_.readlines())) else: st.error("笔记尚未创建,请点 [保存笔记] 创建!") with st.beta_expander("笔记设置"): st.text("视频名称:" + self.player_open_file_s_name) st.text("笔记文件:" + self.book_note_file_path) book_note_description_text = st.text_area("笔记描述") for i in range(1, self.question_input_form_num + 1): book_note_question = st.text_input(str(i) + ".问题") book_note_answer = st.text_area(str(i) + ".答案") # 要写入的内容 s_question_answer_content = s_question_answer_content + "rnrn{}: {}rnrn{}: {}" .format("Q", book_note_question.rstrip(" "), "A", book_note_answer.rstrip(" ")) if st.button("保存笔记"): if not os.path.exists(self.player_open_file_name): st.error("没有正在播放的视频,请先打开要播放的视频!") else: # 创建文件 if not os.path.exists(self.book_note_file_path): with open(self.book_note_file_path, "w") as f_: if book_note_description_text: f_.writelines("{}{}{}".format("######[", book_note_description_text, "]######")) else: f_.writelines("######[描述信息]######") f_.writelines(s_question_answer_content) else: # 读取文件 with open(self.book_note_file_path, "r") as f_: # 匹配描述信息(所有字符) pattern = re.compile(r"######([sS]*)######") s_line_str_list = [] # 最终写入的内容 for s_line_str in f_.readlines(): if pattern.match(s_line_str): # st.write(pattern.match(s_line_str)) s_desc_text = pattern.match(s_line_str).groups()[0] # 修改描述信息 if book_note_description_text != s_desc_text: # 如果没有输入描述,写入默认 if book_note_description_text.strip(" ") == "": book_note_description_text = "在此输入你的描述信息" s_line_str_list.append( "######[" + book_note_description_text + "]######") else: s_line_str_list.append("######[" + s_desc_text + "]######") elif len(s_line_str.strip().strip(" ")) > 0: s_line_str_list.append(s_line_str.strip()) # 添加的答案信息 s_question_answer_list = [_str for _str in s_question_answer_content.split("rn") if len(_str.strip(" ")) > 0] s_line_str_list.extend(s_question_answer_list) # st.write(s_line_str_list) # 最终写入的内容 book_note_all_content = "rnrn".join(s_line_str_list) # 保存文件 with open(self.book_note_file_path, "w") as f_: f_.writelines(book_note_all_content) st.success("笔记创建成功!") st.balloons() # 气球效果 # 显示右侧的字幕内容 with col2: # 显示关键词 with st.beta_expander(label="查看关键词", expanded=True): st.markdown("{}{}{}".format("", self.keywords_stat_content_str, "")) st.text("") # st.write("rn**".join(self.srt_word_content.split("xx:"))) # st.markdown("<hr>", unsafe_allow_html=True) # st.components.v1.html("<hr>") # 显示字幕信息 st.text_area("视频讲话内容", value="rn".join(self.srt_all_content.split("xx:")), height=1600, max_chars=None, key=None) # line_str_list = [line_str.strip() re.find("d", line_str).match()] # st_content = ("".join(line_str_list)) # <br> # 结束 st.markdown("<hr>", unsafe_allow_html=True)# 程序类入口if __name__ == '__main__': video_main = VideoShowMain() video_main.ui_main()三. 获取视频
方法有很多种,为了和之前知识联系起来,除常规下载外你也可以使用之前的MPV视频在线剪辑方法截取网上长视频的部分视频片段到本地磁盘. 此外还可以对在线播放的视频使用视频录制功能保存下来,直接使用ffmpeg或者PotPlayer就可实现.
1. 如是是MPV播放器,使用如下链接中的方法,播放时通过字母C选定开头及结尾,使用字母O键导出录制,直接在MPV播放器界面上操作即可,这种方式基本原理上是使用了ffmpeg的 -i 参数.
一只小胖子:MPV播放器系列(一)-剪辑在线视频zhuanlan.zhihu.com
2.如果你使用的是PotPlayer播放器的话,它有个录制的功能,直接使用它自带的录制功能即可.
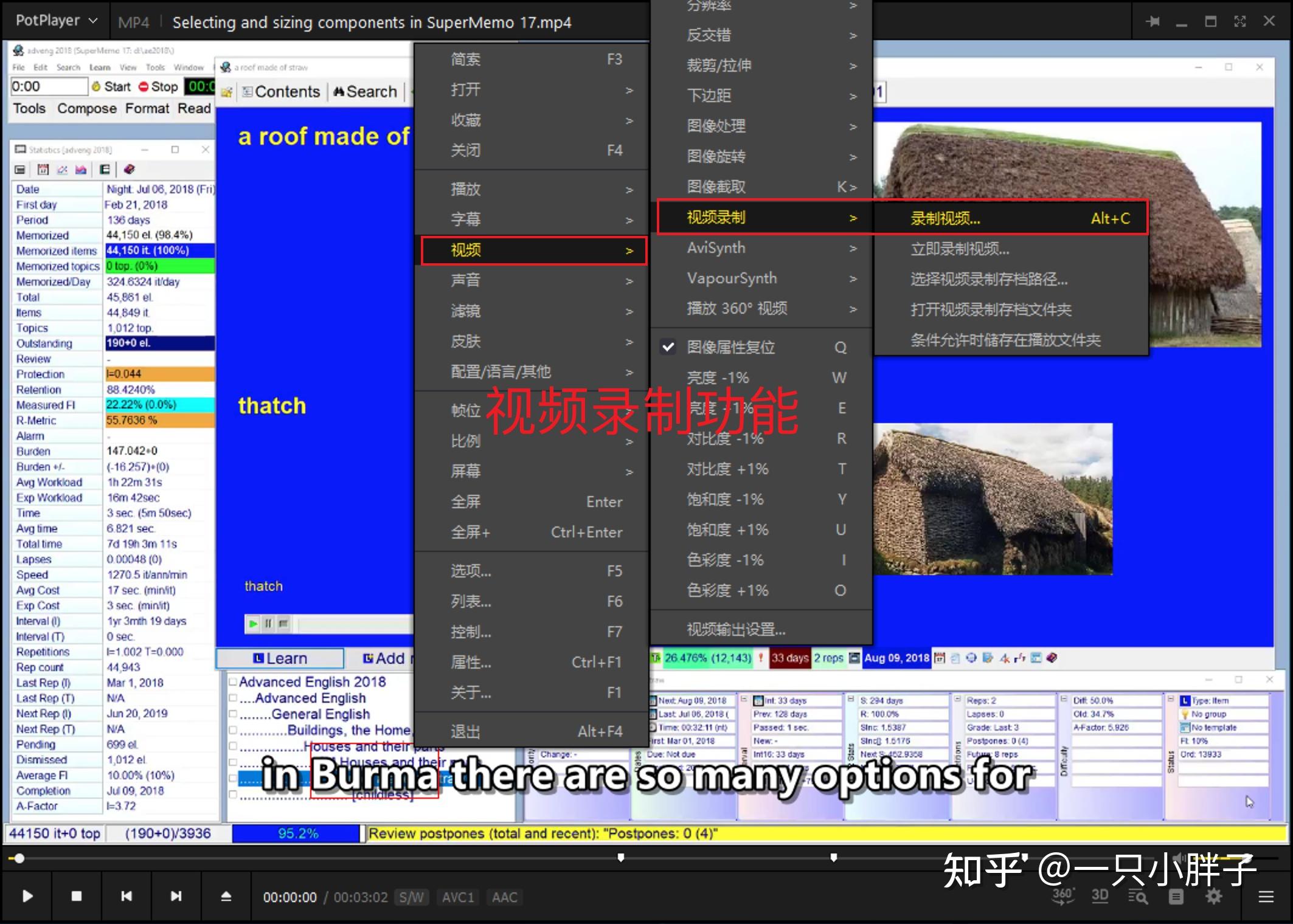
## 录视频ffmpeg -framerate 30 -f avfoundation -i 0 out.mp4 -framerate 限制视频的采集帧率。这个必须要根据提示要求进行设置,如果不设置就会报错。-f 指定使用 avfoundation 采集数据。-i 指定视频设备的索引号。##视频+音频ffmpeg -framerate 30 -f avfoundation -i 0:0 out.mp4 ## 录音ffmpeg -f avfoundation -i :0 out.wav四. 生成字幕
字幕文件生成我使用的是一款开源软件.在之前的文章中我有详细介绍过.当然,市面上有多种方案来提取字幕信息,适合自己就是好的.我推荐你使用VideoSrt或者使用ffmpeg / pydub / 百度API语音接口自己开发等两种方式来实现,主要是开源,高度可定制化,实现起来也不复杂.
如果你不会代码也没有关系,我这里讲解的是VideoSrt,直接配置下使用就好. VideoSrt是一款开源的批量一键字幕生成 / 字幕翻译小工具可以通过自定义配置来支持调用腾讯/阿里/百度/迅飞等厂商提供的语音引擎.你可以参考如下的链接:
一只小胖子:常见的-语音转文本及字幕方案zhuanlan.zhihu.com如上: 项目链接上提供了详细的说明以及B站的示例操作,按操作一步步配置下就可以使用了,下图是我配置好后批量视频转字幕后的效果.
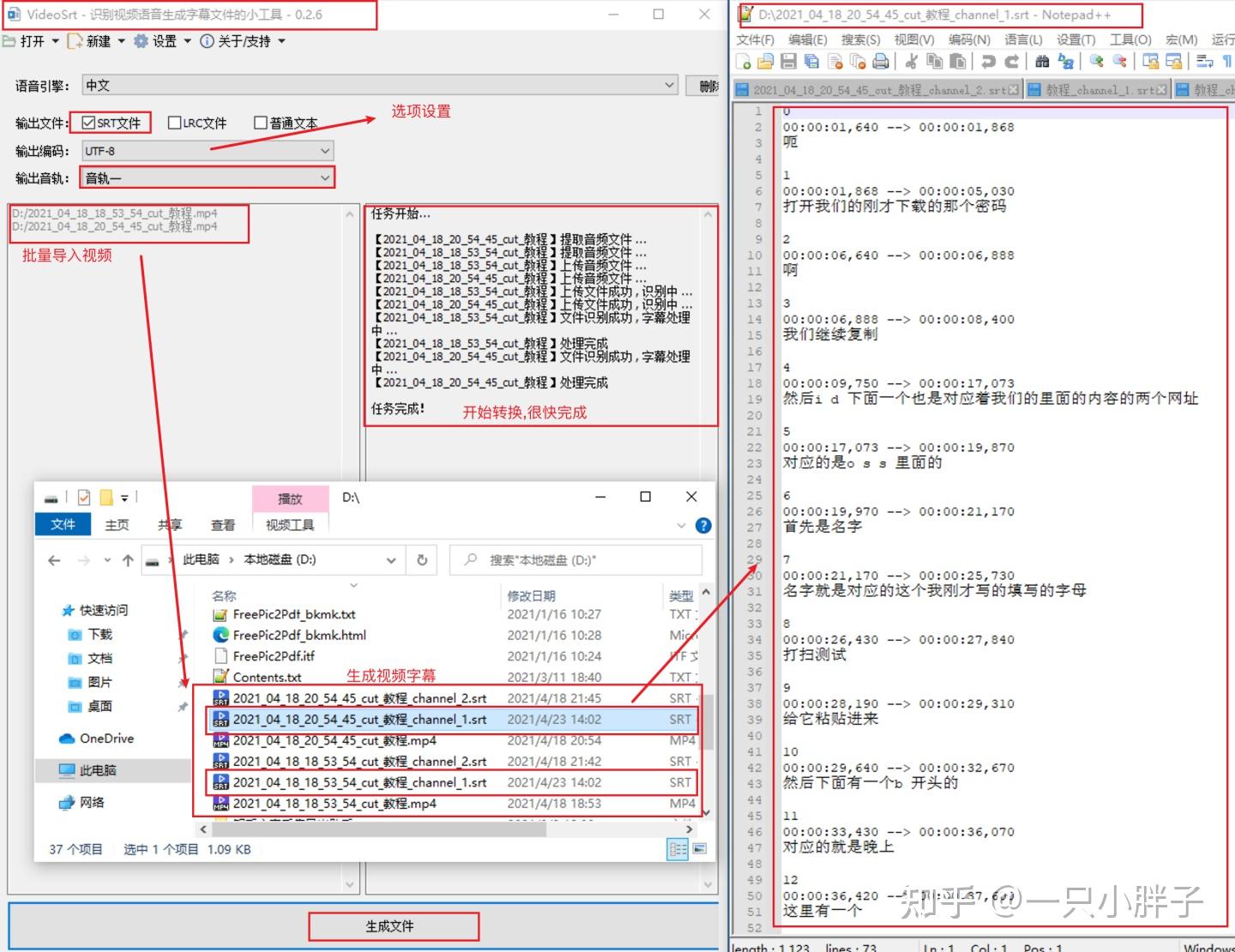
至此,你就可以愉快的在一个界面完成所有的操作了,快速搜索及打开视频,控制播放,分析字幕内容,实时对每个播放视频保存笔记了.....
本文结束...
我是一只热爱学习的小胖子,如果你也热爱学习,并且对SuperMemo感兴趣,欢迎转发和评论!
[Streamlit 视频交互式笔记] 相关文章推荐:
- 最新读后感
- 热门读后感
- 热门文章标签
全站搜索