Intro to RL Chapter 4: Dynamic Programming
时间: 2021-04-26 23:05:32 | 作者:斑马 | 来源: 喜蛋文章网 | 编辑: admin | 阅读: 103次
- 2023-11-24 11:00:14写好读书笔记对写作有哪些帮助
- 2023-11-09 01:01:18读书笔记的摘要和主要内容概述的区别
- 2023-10-30 19:00:44读书笔记对于阅读的重要性体现在哪里
- 2023-10-18 13:00:23用平板做读书笔记,推荐哪个软件
- 2023-09-20 11:00:39读书笔记就是摘抄句子吗
- 2023-08-29 17:01:33写读书笔记可以抄正在学的课文吗
- 2023-08-03 11:01:44你对读书笔记或者日记这种手写文字有怎样的认知 是不是和我一样有一种戒不掉的隐 你知道为什么么
- 2023-07-14 19:00:23如何写读书笔记,
- 2023-06-30 23:00:14如何教三年级学生学会写读书笔记
- 2023-06-29 12:01:30怎样引导孩子写读书笔记的感悟思考

4.1 Policy Evaluation (Prediction)
首先思考计算任意
4.2 Policy Improvement
得到了一个policy的value function,就可以更新policy。首先考虑deterministic policy(本章中方法皆可扩展到stochastic policy)。考虑在一个state4.3 Policy Iteration
不断做policy evaluation和policy improvement,每一步都可以得到strictly better policy,最终可以得到optimal policy。这种方法称为policy iteration 这种方法的速度越来越快(猜的,因为value function的变化越来越小)。通常很快就收敛了。
这种方法的速度越来越快(猜的,因为value function的变化越来越小)。通常很快就收敛了。4.4 Value Iteration
一个policy iteration的缺点是,每次都要policy evaluation。我们不必每次都等value function收敛,如value iteration: value iteration每一步包含一步policy evaluation,一步policy improvement。通常一步policy improvement + 几步policy evaluation会收敛更快。
value iteration每一步包含一步policy evaluation,一步policy improvement。通常一步policy improvement + 几步policy evaluation会收敛更快。4.5 Asynchronous Dynamic Programming
之前讨论的DP方法,都需要将state重复扫。asynchronous DP用任意顺序,利用任何available的下一步数据。有的数据可能更新几次了,有的可能还没更新,有的利用out-of-date数据更新。需要保证不忽略states,但很flexible。in-place iterative methods。比如有一种就是一次只更新一个state,逐个更新。只要保证所有的都能更新无限次就ok。不扫state并不意味着计算量减很多,只是通过选择state来加速,选择更新顺序来让信息流动更迅捷。有了asyn DP,我们也可以让agent和环境交互时,实时更新state value,让算法关注和agent关系更近的states。4.6 Generalized Policy Iteration
policy iteration,value iteration,asyn DP都是policy evaluation和policy improvement的各种结合,最终目标都是找到optimal value function和optimal policy。generalized policy iteration (GPI) 来表示policy evaluation和policy improvement的交互。大部分RL方法都可以用GPI表示,即有不同的policy和value function,用value funtion来更新policy,让value function更接近policy的true value funtion。当evaluation和improvement都稳定时,即converge了,得到optimal,满足Bellman equation。policy稳定表示它greedy了当前value function;value function稳定表示它是policy的value function。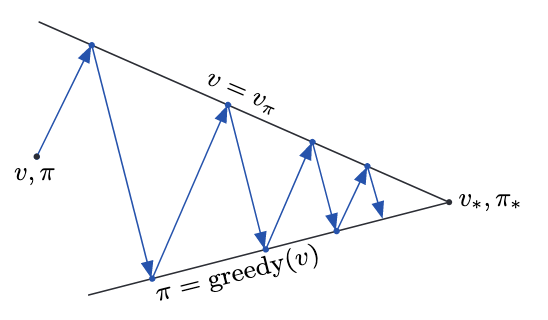
4.7 Efficiency of Dynamic Programming
DP可能不适用于大问题,但其实挺efficient。找到optimal的时间和states actions数成polynomial,而且还能保证找到optimal,比把所有policies都试一次好很多,which is exponential time。DP方法受限于curse of dimensionality,即state数量随着state variable的增长呈exponential growth。policy iteration和value iteration用得都很广泛,很难说哪个更好。一般都比worst case要好很多,尤其是initial policy,value设置得好。state很多时,一般用asyn DP。4.8 Summary
用一个estimate来更新estimate,称为bootstrapping。在RL里很常见。文章标题: Intro to RL Chapter 4: Dynamic Programming
文章地址: http://www.xdqxjxc.cn/duhougan/104315.html
文章标签:读书笔记
[Intro to RL Chapter 4: Dynamic Programming] 相关文章推荐:
- 最新读后感
- 热门读后感
- 热门文章标签
全站搜索