KeyPose:从立体估计透明物体的 3D 姿势
时间: 2021-10-19 12:42:09 | 作者:雨夜的博客 | 来源: 喜蛋文章网 | 编辑: admin | 阅读: 116次
- 2023-09-18 09:01:07米爸讲科学 | 为什么水是透明的,大海却是蓝色的,雪是白色的
- 2023-05-10 12:01:03手上长透明小水泡是什么原因造成的
- 2023-03-13 09:04:56物理科普的渠道有哪些
- 2023-01-02 12:04:32理论物理科普有什么意义
- 2022-12-14 11:01:10玻璃透明原理
- 2022-11-04 15:01:12为什么半透明的TPE手套,沾上油之后会变得晶莹剔透
- 2022-10-26 21:00:18高二 有哪些关于物理科普类的书啊
- 2022-10-22 13:01:22为什么玻璃容器的刻度从外面俯视看刻度不准 从容器里面看就准 若换成不透明的俯视看刻度是否就准了
- 2022-01-02 03:00:56有哪些好的适合高中和大学的物理科普书籍
- 2021-04-13 08:55:05盘点地球上5种透明的奇怪动物,不得不感叹大自然的神奇,透明是最好的保护色

估计 3D 对象的位置和方向是计算机视觉应用程序中涉及对象级感知的核心问题之一,例如增强现实和机器人操作。在这些应用程序中,了解对象在世界中的 3D 位置非常重要,无论是直接影响它们,还是将模拟对象正确放置在它们周围。虽然已经使用机器学习 (ML) 技术,尤其是深度网络对这一主题进行了大量研究,但大多数研究都依赖于深度传感设备的使用,例如Kinect,它可以直接测量到物体的距离。对于有光泽或透明的物体,直接深度感应效果不佳。例如,下图包括多个物体(左),其中两个是透明的星星。深度设备无法找到良好的恒星深度值,并且对实际 3D 点的重建非常差(右)。
此问题的一种解决方案,例如ClearGrasp提出的解决方案,是使用深度神经网络修复透明对象损坏的深度图。给定透明物体的单个 RGB-D 图像,ClearGrasp 使用深度卷积网络来推断表面法线、透明表面的掩码和遮挡边界,它用于细化场景中所有透明表面的初始深度估计(最右边 )上图)。这种方法非常有前途,并且允许通过依赖深度的姿势估计方法处理具有透明物体的场景。但是修复可能很棘手,尤其是在完全使用合成图像进行训练时,仍然可能导致深度错误。
在“ KeyPose: Multi-View 3D Labeling and Keypoint Estimation for Transparent Objects ”中,与斯坦福人工智能实验室合作在CVPR 2021上发表,我们描述了一个 ML 系统,它通过直接预测 3D 关键点来估计透明物体的深度。为了训练系统,我们以半自动化的方式收集透明物体图像的大型真实世界数据集,并使用手动选择的 3D 关键点有效地标记它们的姿势。然后,我们训练深度模型(称为 KeyPose)以从单目或立体图像端到端地估计 3D 关键点,而无需明确计算深度。对于单个对象和对象类别,这些模型都适用于训练期间可见和不可见的对象。虽然 KeyPose 可以处理单眼图像,但立体图像中可用的额外信息使其结果比单眼图像输入提高了两倍,典型误差为 5 毫米到 10 毫米,具体取决于对象。即使在为竞争方法提供真实深度时,它也大大提高了这些对象的姿态估计的最新技术水平。我们正在发布供研究界使用的关键点标记透明对象数据集。
带有 3D 关键点标签的真实世界透明对象数据集
为了便于收集大量真实世界图像,我们建立了一个机器人数据收集系统,其中一个机器人手臂通过轨迹移动,同时使用两个设备、一个立体摄像头和一个摄像头拍摄视频。在Kinect的Azure的深度相机。
该AprilTags目标使相机的姿态进行准确跟踪。通过使用 2D 关键点手动标记每个视频中的少数图像,我们可以使用多视图几何为视频的所有帧提取 3D 关键点,从而将标记效率提高 100 倍。
我们为五个类别的 15 个不同的透明物体捕获图像,使用 10 种不同的背景纹理和每个物体的四种不同姿势,产生总共 600 个视频序列,包括 48k 立体和深度图像。我们还使用对象的不透明版本捕获了相同的图像,以提供准确的地面实况深度图像。所有图像都标有 3D 关键点。我们正在公开发布这个真实世界图像数据集,以补充与它共享相似对象的合成 ClearGrasp 数据集。
KeyPose Algorithm Using Early Fusion Stereo
这个项目独立开发了直接使用立体图像进行关键点估计的想法;它最近也出现在手部追踪的背景下。下图显示了基本思想:来自立体相机的两幅图像围绕对象裁剪并馈送到 KeyPose 网络,该网络预测表示对象 3D 姿态的稀疏 3D 关键点集。网络使用来自标记的 3D 关键点的监督进行训练。
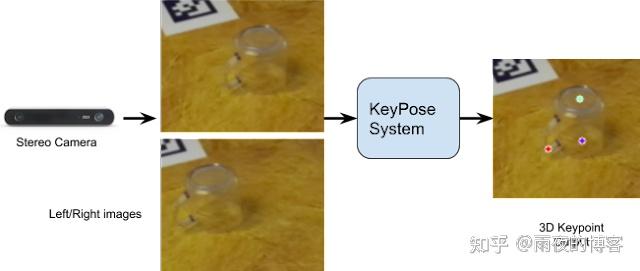
立体 KeyPose 的一个关键方面是使用早期融合来混合立体图像,并允许网络隐式计算视差,与后期融合相反,后者分别为每个图像预测关键点,然后组合。如下图所示,KeyPose 的输出是图像平面中的 2D 关键点热图以及每个关键点的视差(即逆深度)热图。这两个热图的组合为每个关键点生成关键点的 3D 坐标。

与后期融合或单眼输入相比,早期融合立体声的准确度通常是后者的两倍。
结果
下图显示了 KeyPose 在单个对象上的定性结果。左边是原始立体图像之一;中间是投影到图像上的预测 3D 关键点。在右侧,我们将瓶子 3D 模型中的点可视化,放置在由预测的 3D 关键点确定的姿势上。该网络高效且准确,在标准 GPU 上仅使用 5 毫秒即可预测关键点,瓶子的 MAE 为 5.2 毫米,杯子的 MAE 为 10.1 毫米。


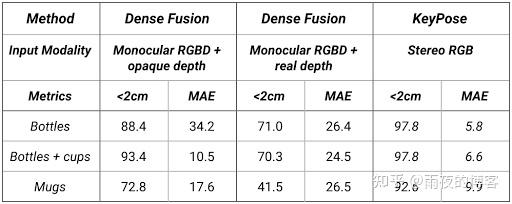
下表显示了 KeyPose 在类别级别估计上的结果。测试集使用了训练集看不到的背景纹理。请注意,MAE 从 5.8 毫米到 9.9 毫米不等,显示了该方法的准确性。
有关定量结果以及消融研究的完整说明,请参阅论文和补充材料以及KeyPose 网站。
结论
这项工作表明,可以在不依赖深度图像的情况下,从 RGB 图像中准确估计透明物体的 3D 姿态。它验证了使用立体图像作为早期融合深度网络的输入,其中训练网络直接从立体对中提取稀疏 3D 关键点。我们希望广泛的、标记的透明对象数据集的可用性将有助于推动该领域的发展。最后,虽然我们使用半自动方法来有效地标记数据集,但我们希望在未来的工作中采用自我监督的方法来消除手动标记。
更新说明:优先更新微信公众号“雨夜的博客”,后更新博客,之后才会陆续分发到各个平台,如果先提前了解更多,请关注微信公众号“雨夜的博客”。
博客来源:雨夜的博客
[KeyPose:从立体估计透明物体的 3D 姿势] 相关文章推荐:
- 最新经典文章
- 热门经典文章
- 热门文章标签
全站搜索